
Last week I recreated the Hacker News site. It is built as a isomorphic site with a Prism compiled frontend and a Rust backend. In this post I will illustrate some of the benefits that using Prism compiler has on this site. Repo
Isomorphic sites with a Rust backend
Currently most sites are client side rendered apps built with a framework. Client side frameworks make development easier by using a more declarative programming style. Using the client runtime can add more reactive interactions without going back to the network. Client side frameworks make SPA’s easier to develop.
However a pure client side site lacks fast start up times. Before any content is added to the DOM JavaScript must be downloaded, parsed and executed. This relies on the the network speed and speed of the client device. There is also the problem that if this process fails then you end up with a solid white page. Another problem is that each request returns the same HTML so there are problems with SEO and link previews.
Client side rendering is acceptable for mostly interactive sites (e.g. figma) but does not suit more contentful sites where content is more important than reactivity.
So there is a return to server side rendering (SSR). Where instead of creating content with JS on the client the server returns markup on the initial request. SSR fixes the above problems as there is no reliance of the client runtime for content. SSR responses contain relevant non-unique markup so link previews are now possible and SEO increases.
Server side rendering a client side app is possible already with things like renderToString from react-server/dom and the render exposed on svelte components. Then there are isomorphic frameworks like Nextjs and sapper which tie this all in together.
And this is true for the HN site, it correctly renders pages on the server as reading posts and comments is more important than interactions.
However all of these methods are limited to the JavaScript runtime
That limit prevents:
- Performance improvements
- Language dependant libraries on the backend
- Existing in house code written in that language
Which are all big drawbacks
So I created my own framework Prism to fix this:
Prism can compile to native fast rust functions. All .prism components are compiled to native rust string concatenation functions. Changes to .prism component markup will change the rust functions thus there are no desync issues. This has many benefits:
- Single source, DX speed, no need to rewrite for server contexts
- Changes to prism components are reflected and kept inline with the rust methods
- Client side markup and server side markup are kept in sync preventing hydration issues.
It also compiles across the interface to struct which retains the strong type safety. The rust compiler will pick up any other issues with the outputted rust functions. This is a step above handlebars where malformed errors are left to runtime.
It is not as complete as Nextjs as where it builds the whole backend for you. Prism only builds out functions which then must be connected up. But I prefer this design as getting data on the server and the client is very different (not for this example but for applications where you have full control over the stack). Prism is not really a isomorphic framework but more a frontend framework which compiles to Rust modules that expose render methods.
Rust speed is a improvement for responsiveness, reduces server strain allowing for more request per sec, better scaling and reducing costs.
Prism hacker news uses actix-web under the hood which is in the top 5 fastest backend frameworks in the tech empower benchmarks, of that list raw NodeJS server places 152nd. According to the benchmarks it makes actix-web 7x faster than a raw nodejs server.
For this example it doesn’t really make much of a difference as the biggest time here is making HTTP requests to the HN api. A single request to the homepage takes 11 http requests with a lot of them being chained.
Aside from the speed improvements it also means that if you have written your REST api in Rust that you can add SSR to your site reusing the same server and logic rather than having to rewrite server side data fetching in a new nodejs server.
It is already possible to server render SPAs in other languages:
- Through calling directly to v8 api. This still has the overhead and isn’t fast as compiling to native. Lose strong typing. Complex to implement.
- Rewriting in handlebars etc, this has the need to do more work. Changes to frontend markup views must be reflected in the handlebars templates. Can lead to nasty hydration issues (where the frontend logic was not expecting that result from backend)
- Hosting SSG. Sites can be built using a JAM stack pattern where changes to data are then used to. But as said before this doesn’t really work for many sites. Especially HN where the data source is constantly changing with the stories, comments and upvotes.
JIT state hydration
When building isomorphic sites it often makes the frontend more confusing. Now the frontend it is not the start of the world and there is existing markup. The biggest issue from this is booting up state on the frontend. With both server and client rendered DOM the view is the same but the JS state is not there on server responses. Getting the state in JS by doing a data fetch is not good as it may be out of sync with what the server content is. So the approach used by most SSR frameworks is to send down a JSON or JS blob in a script tag that contains the JS object used to generate the markup response.
This is a common practise and can be seen on nytimes where ~75% of the home page response is the state loaded into the window.__preloadedData variable

There are a few things issues with this approach:
- Some of the object is not used. There some impls that use
Proxys to identify unused “leaves” but this is complex and expensive to do. - The data is already sent down in the markup
- Parsing JS objects are slow but using JSON lacks ability to represents types other than string, number, boolean, object and array. This is biggest seen with DateTime.
Then there is partial hydration. From what I have seen this is improvements on the current hydration situation. It works by reducing the number of components hydrated but still seems to suffer from many of the mentioned problems just on a smaller scale.
Prism instead does something more radical. Prism’s approach ditches any sort of JSON or JS blob and the server response only sends markup:

But can still get the state of the application at runtime:

So how does it do this?
As Prism is a compiler it knows the bindings at build time. From that it can compile in getters for each property that access the DOM. Once values are retrieved from the DOM they are cached into the component state and will act the same way as if the data was instantiated on the client.
The runtime does this in quite a special way as to be efficient. Getting the data is only done once that member is evaluated, rather on document / component load. JSON stringify will evaluate the whole object and evaluate every member. But in practise you may only want a specific property. If you evaluate temp1.data.stories[2].title it will only load in the 3rd story and from the story only the title property rather than bringing in every story and constructing the whole state (not that the getters are slow, in practise getting the state as JSON took 6ms but in applications with more than 10 stories on the home page the improvement is visible).
Some of the advantages of JIT state hydration over current hydration techniques:
- Smaller payload sizes
- Simplicity, all a component needs to have data is SSR content.
- The JS payload is expensive as requires JS parsing and data requires memory allocation.
- Complications for objects that cannot be represented in JSON (DateTime 👀)
- Although values in the DOM are all string Prism converts the string to the correct types. As can been seen from the
idandscorevalue on each story in the state. - Values are cached after being pulled after hydration
- Yes there is overhead. Prism compiles getters of around 60 bytes in length. The size of get hydration logic scales on a per property basis. Biggest savings are on state which contains long strings or on large arrays of objects with the same structure.
- The get logic is invariant and can be cached between requests. The JSON blob is not.
Recreating state from the rendered markup is not a new thing. Many existing SSR sites manually write JS in the runtime script to get values. The actual HN site does this in its vote logic to where it pulls in the story id from the elements id:

But Prism is the first to take this a step further and automate this process. This logic in hn.js is hand written and relies on the fact that the server rendered element's id includes the id of the post.
Bundle size
Prism is the (probably )the smallest framework out there. The JS bundle for hacker news is 12.6kb (3.5kb Gzip, 3.2kb Brotli). This is quite impressive as this includes:
- All the render logic for the pages
- All the reactivity
- A spa router
- All the client data fetching logic
So its not a surprise that it gets 100 on lighthouse:
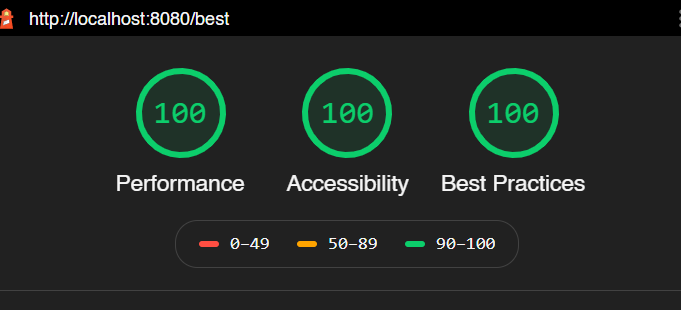
So I would say that Prism compiler builds the smallest bundle sizes. Its also true that 12.6kb of JavaScript is all the JS ever needed. With the JIT hydration there is no need for JS blobs or other stuff to enter the JS client runtime. So although other solutions may say they have 15kb bundle there is likely going to be a extra 10kb of JS on each request for doing state hydration.
Actual HN runs on ~4kb of non compressed JS but then it is not a spa or framework built so I don’t think there is any comparison with it. On the other hand the svelte/sapper HN implementation runs on 30kb of JS (although it doesn’t seem to minified). So Prism is looking very good for small frameworks. But when it comes to these small numbers it doesn’t really matter, as long as its under 50kb of JS its pretty responsive.
Coming back to the size, with any abstraction or automated approach there is bound to be more JS outputted than writing it out by hand. Prism automates a lot of stuff, and provides the declarative approach that exists in all other client side frameworks while keeping the bundle size very low:
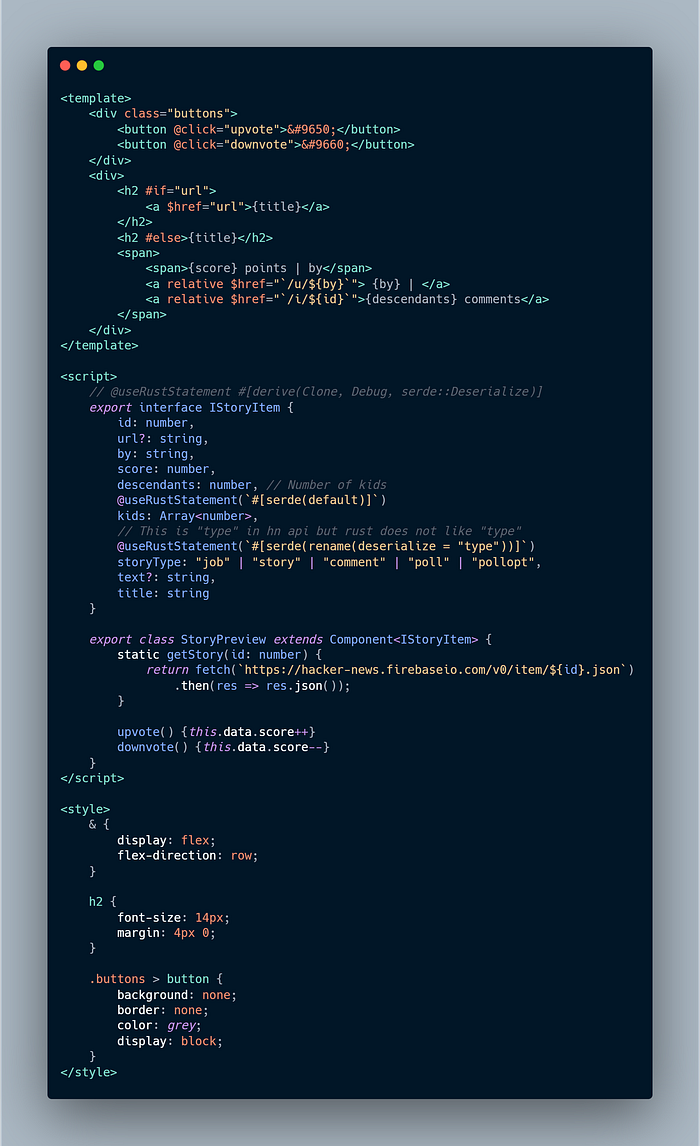
When HN app launches up the custom elements connected events fire and add event listeners on to the existing markup. Here the upvote and downvote buttons on the story preview are added event listeners. Prism recognises that the server ≠ client and all elements with events will be server rendered with the disable attribute (which is removed once the listener is added). Here the button click will fire the upvote method.
In the upvote method it will increment this.data.score. If the value is not already in the data cache it will be hydrated in. The increment operator will then fire a set which under the hood fires a imperative DOM call to update the view and the view will now show score + 1 points.
Prism also has a built in static router. Clicking on the comments anchor tag will route to that stories page. Also this is just a regular anchor tag under the hood so if the JS fails it will do a regular redirect and hit the server.
SPA routing has the benefits over the MPA that HN is. On a redirect it only has to load the data for that new view in and not the whole markup. This can reduce payload over the server. On redirecting the HN header is retained in the DOM and only the page is switched out. Not used here but also animations can be done rather than a flash of content. It also means that this site works without SSR and can be cached in a service worker.
This is only experimental at the moment, there is a lot of stuff hacked together in the compiler to get this to example to work. The compilation is shaky at best and only works for simple examples such as this. This is not a drop in replacement for a nextjs site. And lacks a lot of the reactivity that react, vue and svelte have to offer. However with time and improvement Prism may be a viable option.
For now this is a proposal and a experiment to see whether there are improvements that can be made in this field and from the results of this clone it looks promising.
Future
One improvement that would improve page response times is progressive rendering. Currently the page only starts to render in on the client once the whole server response has been built. Using progressive rendering here would get the header to render in here before the backend has even hit the HN api. With each backend request the response could be immediately sent to the client to be rendered in. This would also work really well with the JIT hydration. Currently a tracked issue but there is decisions to be made of how the exposed function works with partial resolving state.
With the addition of Rust to the target outputs for Prism it proves that there is the ability to construct SSR functions for other languages. The addition took less than 2 weeks to implement and a lot of that was opening up the pipeline to be less language oriented (and a lot of wrangling with Rust’s memory safety model). There is a opportunity to add support for more languages if this is a beneficial feature but I think the Rust implementation needs to be scrutinised and tightened up before that happens.
This clone is also missing a number of features from the actual version that I would still like to implement. But I only spun this example up in a week and before that I had no experience with Rust. Also during development Prism was missing a few features such as recursive components (used for the comments) and unsafe html (HN text field includes raw HTML) so I added them for 1.3.0
For now you can clone the clone and try it out here:
And follow development @kaleidawave
For a JS based isomorphic site there is https://github.com/kaleidawave/prism-ssr-demo and can be run without downloading anything through replit: https://repl.it/github/kaleidawave/prism-ssr-demo
